Importing Data in Python
Before any Data Analysis, what could be better than knowing the types of data to import and how to import them.
In this tutorial we will see how to import files from several sources.
1: Txt Files
A txt file is a file that contains plain (unformatted) text and does not require any special program (software) to open it.
So to open a txt file in python:
fichier = open('roman.txt',mode='r')
print(fichier.read()) The above code produces the following output:

Reading the contents of a txt file in python
Also we can read the content line by line:
with open('roman.txt') as file:
print(file.readline())
2. csv files
The csv file is a type of file whose values are separated by commas, hence its acronym CSV (Comma Separated Values). Basically, the csv file contains data from a table and each row of the table corresponds to a row in the file. With the pandas library one can read a cvs file like this:
#pandas library import
import pandas as pd
#assignment of the path to the file to the file variable
file = 'titanic_sub.csv'
#reading the csv file with the read_csv() function
data = pd.read_csv(fichier)
#data content display
dataThe above code snippet will result in:

Reading a csv file with pandas
Other alternatives are also available with the library Numpy:
3. xlsx files
An xlsx file is an Excel spreadsheet created by Microsoft. it manages data in spreadsheets that are full of cells in them arranged in a grid of rows and columns. It may also contain mathematical functions, graphics, styles and formatting. To read the contents of an excel file:
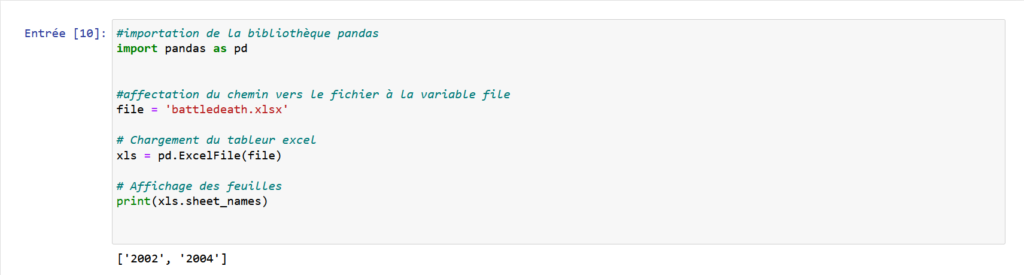
#pandas library import
import pandas as pd
#assignment of the path to the file to the file variable
file = 'battledeath.xlsx'
# Loading the excel spreadsheet
xls = pd.ExcelFile(file)
# Viewing Sheets
print(xls.sheet_names)So we will have as result:
And to read the contents of an excel spreadsheet you can either parse on the name of the sheet or on the index of the sheet; Like this:
# Load sheet into a DataFrame by name: df1
df1 = xls.parse('2004')
# Display of the first five (5) lines of the df1 sheet
print(df1.head())
# Load sheet into a DataFrame by index: df2
df2=xls.parse(0)
# Display of the first five (5) lines of the df2 sheet
print(df2.head())
4. sas files
SAS for (Statistical Analysis System) is a suite of statistical software developed by SAS Institute for data management, advanced analysis, multivariate analysis, business intelligence, predictive analysis, business intelligence etc…
Their extensions are most commonly sas7bdata for datasets and sas7bcat for catalogs. In python there is a sas7bdat module which allows to read a sas file:
#SAS7BDAT import belonging to the sas7bdat module
from sas7bdat import SAS7BDAT
# Saving the file in a Dataframe: df_sas
with SAS7BDAT('sales.sas7bdat') as file:
df_sas= file.to_data_frame()
# Show first 5 rows
print(df_sas.head())
The output will be:

5. stata files
Stata is a statistical and econometric software widely used by economists and epidemiologists. A stata (.dta) file can be read with pandas:
# Panda import
import pandas as pd
# Loading the file into dataframe: df
df=pd.read_stata('disarea.dta')
# Display of the first 5 lines
df.head()
6. MATLAB files
Matrix Laboratory where MATLAB is a digital computing environment that is an industry standard in engineering and science disciplines that advocates powerful linear algebra and matrix capabilities. A MATLAB file has the extension .mat and is a collection of several objects (strings, decimal numbers, vectors, arrays, etc….). To read a .mat file we need scipy.io:
# Package import
import scipy.io
# Loading the MATLAB file: mat
mat = scipy.io.loadmat('ja_data2.mat')
# Display of the type of the mat variable
print(type(mat))
As noted the variable is a dictionary; So we can see the different keys and be able to read the contents:
# Package import
import scipy.io
# Loading the MATLAB file: mat
mat = scipy.io.loadmat('ja_data2.mat')
# Display of the type of the mat variable
print(type(mat))
# Viewing Dictionary Keys
print(mat.keys())
# Viewing rfpCyt Key Values
print((mat['rfpCyt']))

7. SQL files
SQL for Structured Query Language is a language for communicating with relational databases. In this exercise we will use an SQLite database and the SQLAlchemy package to access this database.
So to create a database connection engine we will use SQLAlchemy’s create_engine() function, passing it the type and name of the database as parameters:
# Module import
from sqlalchemy import create_engine
# Creation of the engine and assignment to the variable engine
engine = create_engine('sqlite:///Chinook.sqlite')
# Assignment of table names to variable: table_names
table_names= engine.table_names()
# Display of table names
print(table_names)
After creating the connection engine, it’s time to connect and interact with the database:
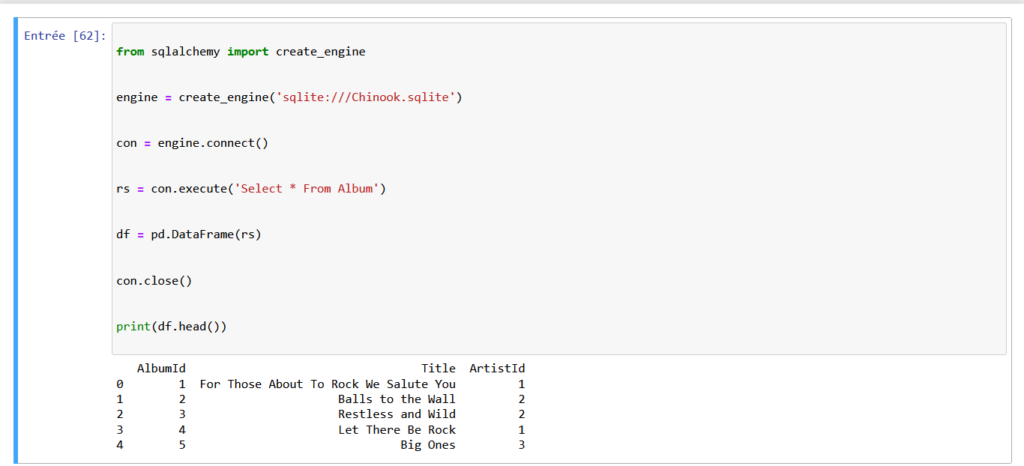
# Open motor connection: con
con = engine.connect()
# Run a query: rs
rs = con.execute('Select * From Album')
# Save result as DataFrame: df
df = pd.DataFrame(rs)
# Closing the connection
con.close()
# Display of the first 5 lines of the query
print(df.head())
Here we were able to interact with the database with SQLAlchemy. Another simpler alternative is to use Pandas to interact directly with the database. This by using the read_sql_query function and as parameters the query and the connection engine
from sqlalchemy import create_engine
engine = create_engine('sqlite:///Chinook.sqlite')
# Execute the query and store the rows in a DataFrame: df
df = pd.read_sql_query('select * from Album', engine)
# Display of the first five(5) lines
print(df.head())
