Tout comprendre sur ETL dans l'ingénierie des données
Introduction
Vous êtes-vous déjà demandé comment votre organisation obtient toutes les informations sur les employés, les salaires et les détails des projets sur un magnifique tableau de bord ? Vous vous demandez comment un Chef obtient toutes ses notes, ses avis consolidés en une seule note ? Vous demandez-vous comment vous obtiendrez une cote de crédit basée sur tous vos antécédents de crédit réunis ?
Bien sûr, une fusion des mathématiques, de l'importance commerciale, de la science et des décisions, etc. fournit ces résultats. Mais, l'aspect le plus important pour en arriver là est DATA. Without data, there would be no valid information.
Nous avons évidemment entendu plusieurs blogs nous dire que 50% des données mondiales sont collectées au cours des deux ou trois dernières années. Les données ne manquent donc pas. Mais, est-ce qu'il suffit d'avoir des données ? Les données dans leur forme originale sont-elles utiles telles quelles ? Le dumping de toutes les données en un seul endroit est-il suffisant pour nous aider dans nos décisions commerciales ou nos tendances ? Et bien non!
Qu'est-ce qu'ETL et comment ça marche ?
Les données doivent subir un processus avant d'être considérées comme utilisables. Par exemple, Or !! Certes, on ne peut pas porter des roches dorées telles quelles. Nous devrons
- Extraire les particules d'or des roches. Cela peut provenir d'une mine ou d'une rivière, sous n'importe quelle forme.
- L'or extrait est fondu, les impuretés sont éliminées, il est fabriqué selon un format standard approuvé, c'est-à-dire Transformer
- Enfin, il peut être transformé en(CHARGER) une alliance ou une ceinture WWE !
Donc, déplacer de l'or (lisez-le comme des données : P), entre différentes parties du système s'appelle l'ETL.
ETL est le processus par lequel les données sont extraites de diverses sources sous leurs diverses formes, transformées pour éliminer les incohérences et améliorer la norme des données, puis chargées dans un endroit cible, à partir duquel des données propres peuvent être utilisées pour analyser, expérimenter, visualiser et prédire les données.
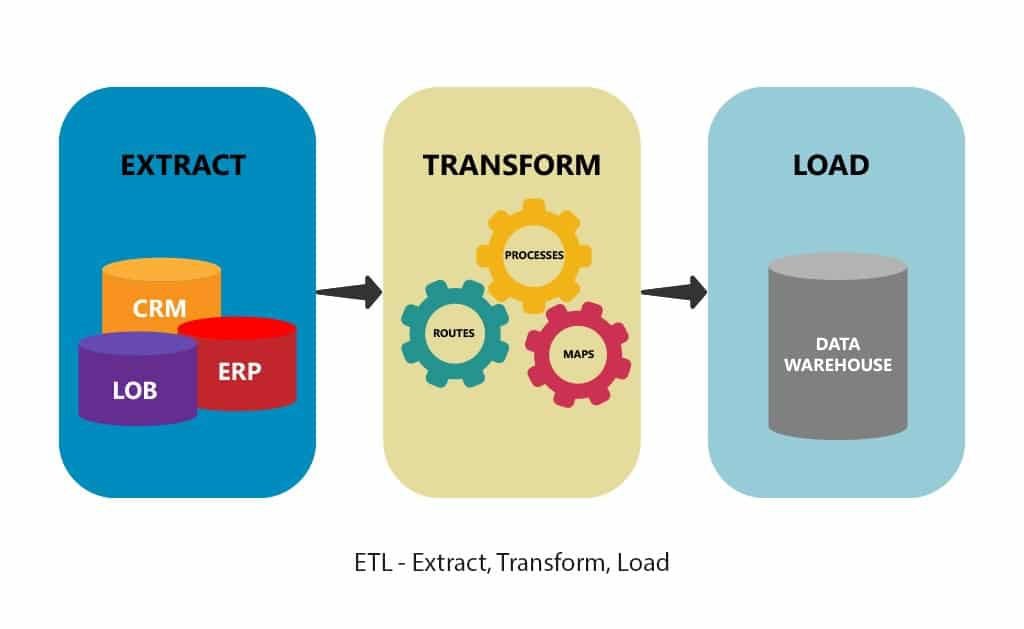
Extraire
Très peu d'entreprises s'appuient sur un seul type de données ou de système. Dans la plupart des cas, les données sont gérées à partir de plusieurs sources et divers outils d'analyse de données sont utilisés pour générer des informations commerciales. Les sources de données les plus couramment utilisées sont les bases de données (DB), les fichiers plats, les services Web, d'autres sources telles que les flux RSS, etc. Pour que ces stratégies de données complexes fonctionnent, les données doivent pouvoir se déplacer librement entre les systèmes et les applications.
Dans la première phase du processus ETL, les données structurées et non structurées sont importées et intégrées dans un référentiel unique. Les données brutes peuvent être extraites d'un éventail de sources et déplacées vers la zone de préparation.
Une zone de transit ou zone d'atterrissage est une zone de stockage intermédiaire utilisée pour le traitement des données pendant le processus d'extraction, de transformation et de chargement (ETL). La zone de transit est utilisée pour valider les données extraites avant de les transférer vers le système cible, la base de données ou l'entrepôt de données.
Transformer
Après l'extraction réussie des données, elles passent à l'étape suivante, la transformation. Pour assurer la qualité et l'accessibilité des données, pour faciliter une interrogation efficace, les données sont transformées. C'est l'une des étapes les plus importantes du processus ETL. La raison en est que ce que nous alimentons est ce que nous retirons ! Si nous alimentons des données erronées et incomplètes, cela entraînerait de mauvaises informations, une analyse incorrecte, et tout le cas d'utilisation se résumerait à un échec.
Cette étape implique,
- Nettoyage : résout les incohérences de données et les valeurs manquantes.
- Normalisation : les règles de formatage sont appliquées à l'ensemble de données.
- Déduplication : les données redondantes sont exclues ou supprimées.
- Vérification : Les données inutilisables sont supprimées et les anomalies sont signalées.
- Trier : Les données sont triées par type.
Certaines autres techniques de transformation incluent la dérivation, le filtrage, le fractionnement, la jonction, la synthèse, l'agrégation et la validation des données. Les données sont transformées en un format utilisable et stockées sous une forme dénormalisée à l'aide d'un ou plusieurs modèles de table dans Data Warehouse.
Charger
This is the final part of our ETL process. This involves migrating the data to the final destination. It could be a data warehouse or database on-premise or on the cloud. This data can be refreshed automatically when new data is extracted and transformed. This neat and organized data is further used by business analysts for visualization and exploration, by data scientists for experimentation and prediction, or other end users.
Cas d'utilisation ETL
Chaque organisation utilise ETL pour gérer les données, les traiter et les rendre exploitables - à utiliser par les parties prenantes, les analystes, les scientifiques, etc. Nous devons utiliser ETL lorsque nous devons,
Migrer les données
Avec l'avènement de technologies nouvelles et avancées, les organisations passent de systèmes hérités à des systèmes plus récents. Cela nécessite une migration des données. Cela implique de transformer les données dans le nouveau format et de les migrer vers la destination.
Entreposage de données
Un entrepôt de données est une base de données dénormalisée dans laquelle toutes les données extraites et transformées sont chargées. Ce référentiel de données est interrogé à de nombreuses fins.

Intégration de données
Que ce soit pour le marketing ou pour l'IoT, ETL est utilisé pour collecter des données à partir de réseaux sociaux, d'analyses Web, d'appareils, de capteurs, etc., et le tout en un seul endroit pour l'analyse de marché, l'intégration de données IoT et d'autres intégrations.
Réplication de base de données
Les données sont déplacées à partir de bases de données sources telles que Microsoft SQL Server, Cloud SQL pour PostgreSQL, MongoDB ou autres et copiées dans un entrepôt de données. ETL peut être utilisé pour répliquer les données pour cette opération ponctuelle ou un processus en cours.
Machine Learning et L'intelligence Artificielle
Dans le cas d'utilisation le plus important, le système apprend des données à l'aide de techniques d'intelligence artificielle. Les données collectées peuvent être utilisées à des fins d'apprentissage automatique.
ELT et ETL
En parlant de ML, les scientifiques et les analystes des données préfèrent d'abord charger toutes les données, puis, sur la base des données brutes, tracer le processus de transformation des données en fonction des besoins et de la recherche du cas d'utilisation à portée de main. En bref, les données brutes seraient d'abord extraites, chargées, puis transformées. Ce processus est appelé Extract, Load, and Transform(ELT).

ETL nécessite l'exécution d'un processus de transformation avant le chargement dans le système cible. Avec ELT, le système cible est utilisé comme lieu d'exécution des processus de transformation. Des cas d'utilisation complexes appliquent l'ELT où Data Lake est utilisé comme référentiel pour stocker un vaste volume de données brutes.
Alors que Data Warehouse stocke des données structurées et filtrées, Data Lake stocke des données non filtrées et hétérogènes telles quelles. L'ELT donne aux organisations la flexibilité de transformer les données brutes à tout moment, quand et comme nécessaire pour un cas d'utilisation, et n'a pas à se soucier de la transformation en tant qu'étape dans un pipeline de données.
Outils de pipeline ETL
Les données sont au cœur d'une organisation, et ETL joue un rôle important pour les maintenir à jour. Nous sommes confrontés à deux options pour effectuer l'ETL. Nous pouvons réaliser la magie d'ETL en utilisant deux méthodes, la première est le script. c'est-à-dire, construire nos propres outils ETL à partir de zéro en utilisant un langage de programmation et l'autre utilise des outils ETL déjà construits.
"Data is the new gold!ils disent. Les données sont nécessaires à la demande, facilement et rapidement dans leur forme la plus propre. Pour faciliter cela, de plus en plus de techniques de transformation sont utilisées aujourd'hui. Les entreprises peuvent obtenir des informations, tirer des décisions, effectuer des analyses percutantes en utilisant des données uniquement après le processus magique de l'ETL!
Avant d'utiliser les données pour créer de beaux tableaux de bord employés, l'équipe RH a besoin de données bien organisées, avant qu'un chef ne soit noté ; les avis, les évaluations, les commentaires sont extraits, transformés, chargés à partir d'une source unique de vérité, pour obtenir la cote de crédit, les données de toutes les transactions, l'historique des prêts, le paiement sont combinés et analysés.