Régression linéaire en Python
Introduction:
Les algorithmes de régression prédisent des valeurs continues à partir de variables prédictives. Prédire le prix d'une maison en fonction de ses caractéristiques est un bon exemple d'analyse de régression. Dans cet article, je vais implémenter une régression linéaire univariée (une variable) en python.
Régression linéaire? Qu'est-ce que ça veut dire ?
La régression linéaire est un algorithme qui trouvera une ligne droite qui se rapproche le plus possible d'un ensemble de points. Les points représentent les données d'entraînement.
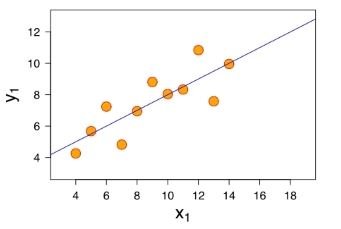
Nos points en orange sont les données d'entrée. Ils sont représentés par le couple (x_{i}, y_{i}). Les valeurs x_{i} sont les variables prédictives, et y_{i} est la valeur observée (le prix d'une maison par exemple). On cherche à trouver une droite F(x) = \alpha*x + \beta telle que, quel que soit x_{i}, on veuille F(x_{i}) \approx y_{i}.
In other words, we want a line that is as close as possible to all the points of our training data.
Présentation du problème
Le problème que nous essayons de résoudre et son jeu de données sont ceux d'un cours que j'ai suivi Andrew NG’s Machine Learning on Coursera. At the time I had to implement the solution in MATLAB. I can assure you it was not my cup of tea. 😉
Le problème à résoudre est le suivant :
Supposons que vous soyez le PDG d'une franchise de food truck. Vous envisagez différentes villes pour ouvrir un nouveau point de vente. La chaîne a déjà des camions dans différentes villes et vous avez des données sur les bénéfices et les populations de la ville.
You want to use this data to help you choose the city to open a new point of sale there.
Ce problème est de type apprentissage supervisé qui peut être modélisé par un algorithme de régression linéaire. Il est de type supervisé car pour chaque ville ayant un certain nombre d'habitants (variable prédictive X), on dispose du gain réalisé dans cette dernière (la variable que l'on cherche à prédire : Y).
Format de données
Les données d’apprentissage sont au format CSV. Les données sont séparés par des virgules. La première colonne représente la population d’une ville et la deuxième colonne indique le profit d’un camion ambulant dans cette ville. Une valeur négative indique une perte.
\end
\end
Le nombre d’enregistrements de nos données d’entrées est 97.
Le fichier est téléchargeable depuis mon espace Github: https://github.com/ybenzaki/univariate_linear_regression_python ici
Pour résoudre ce problème, on va prédire le profit (la variable Y) en fonction de la taille de la population (la variable prédictive X)
Chargement des données
Tout d’abord, il faudra lire et charger les données contenues dans le fichier CSV. Python propose via sa librairie Pandas des classes et fonctions pour lire divers formats de fichiers dont le CSV. Pandas library classes and functions to read various file formats including CSV.
import pandas as pddf = pd.read_csv("D:\DEV\PYTHON_PROGRAMMING\univariate_linear_regression_dataset.csv") |
La fonction read_csv(), renvoie un DataFrame. Il s’agit d’un tableau de deux dimensions contenant, respectivement, la taille de population et les profits effectués. Pour pouvoir utiliser les librairies de régression de Python, il faudra séparer les deux colonnes dans deux variables Python.
#selection de la première colonne de notre dataset (la taille de la population)
X = df.iloc[0:len(df),0]
#selection de deuxième colonnes de notre dataset (le profit effectué)
Y = df.iloc[0:len(df),1]Les variables X et Y sont maintenant de simples tableaux contenant 97 éléments.
Note :
La fonction len() permet d’obtenir la taille d’un tableau
La fonction iloc permet de récupérer une donnée par sa position
iloc[0:len(df),0] permettra de récupérer toutes les données de la ligne 0 à la ligne 97 (qui est len(df)) se trouvant à la colonne d’indice 0
iloc[0:len(df),0] will retrieve all data from line 0 to line 97 (which is len(df)) located at column index 0
Visualisation des données
Avant de modéliser un problème de Machine Learning, il est souvent utile de comprendre les données. Pour y arriver, on peut les visualiser dans des graphes pour comprendre leur dispersion, déduire les corrélations entre les variables prédictives etc…
Parfois, il est impossible de visualiser les données car le nombre de variables prédictives est trop important. Ce n’est pas le cas ici, on ne dispose que de deux variables : la population et les profits.
Nous pouvons utiliser un graphe de type nuage de points (Scatter plot) pour visualiser les données :
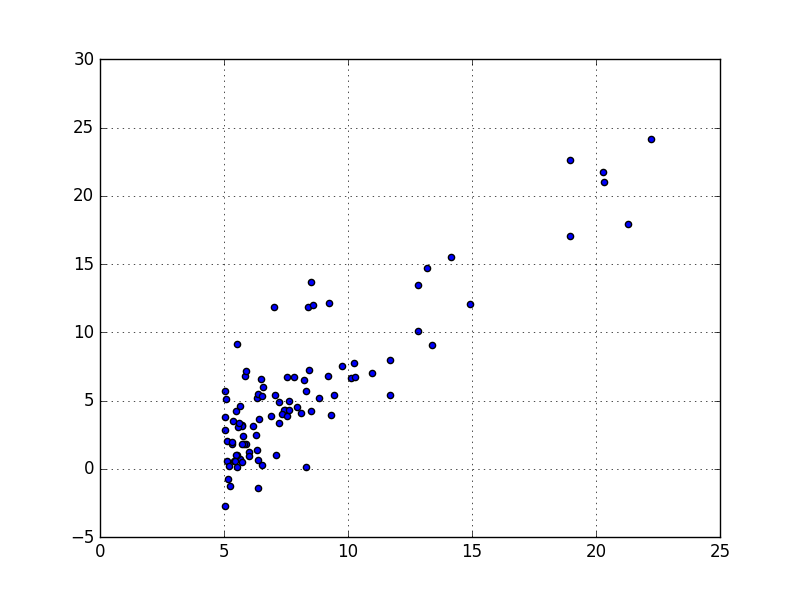
On voit clairement qu’il y a une corrélation linéaire entre les variables. Et que plus la taille de la population augmente, plus le profit en fait de même.
Le code Python permettant d’effectuer ce nuage de points est le suivant :
import matplotlib.pyplot as plt
axes = plt.axes()
axes.grid() # dessiner une grille pour une meilleur lisibilité du graphe
plt.scatter(X,Y) # X et Y sont les variables qu'on a extraite dans le paragraphe précédent
plt.show()Note :
Matplotlib est la librairie python permettant de faire des graphes de plusieurs types :
Histogrammes
Nuages de Points,
Dessiner des courbes de fonctions
Des schémas camembert (Pie plot)
etc…
Appliquer l’algorithme
Maintenant qu’on comprend mieux nos données, nous allons attaquer le cœur du problème : Trouver une fonction prédictive F(X) qui prendra en entrée une taille de population, et produira en sortie une estimation du gain espéré. L’idée du jeu est que la prédiction soit proche de la valeur observée F(X) \approx Y.
Note : Par souci de simplicité, j’ai fait le choix de ne pas découper mes données issues du fichier CSV en Training Set et Test Set. Cette bonne pratique, à appliquer dans vos problématiques ML, permet d’éviter le sur-apprentissage. Dans cet article, nos données serviront à la fois à l’entrainement de notre algorithme de régression et aussi comme jeu de test.
Pour utiliser la régression linéaire à une variable (univariée), on utilisera le module scipy.stats. Ce dernier dispose de la fonction linregress, qui permet de faire la régression linéaire. scipy.stats module. The latter has the linregress function, which allows you to do linear regression.
from scipy import stats
#linregress() returns several return variables. We will be interested
# especially on slope and intercept
slope, intercept, r_value, p_value, std_err = stats.linregress(X, Y)Effectuer des prédictions
Après que la fonction linregress() nous ait renvoyé les paramètres de notre modèle : slope et intercept, on pourra effectuer des prédictions. En effet, la fonction de prédiction sera de la forme :

On peut écrire cette fonction F(x) en python comme suit :
def predict(x):
return slope * x + interceptGrâce à cette fonction, on peut effectuer une prédiction sur nos 97 populations ce qui nous fera une ligne droite.
#the variable fitLine will be an array of predicted values from the array of variables X
fitLine = predict(X)
plt.plot(X, fitLine, c='r')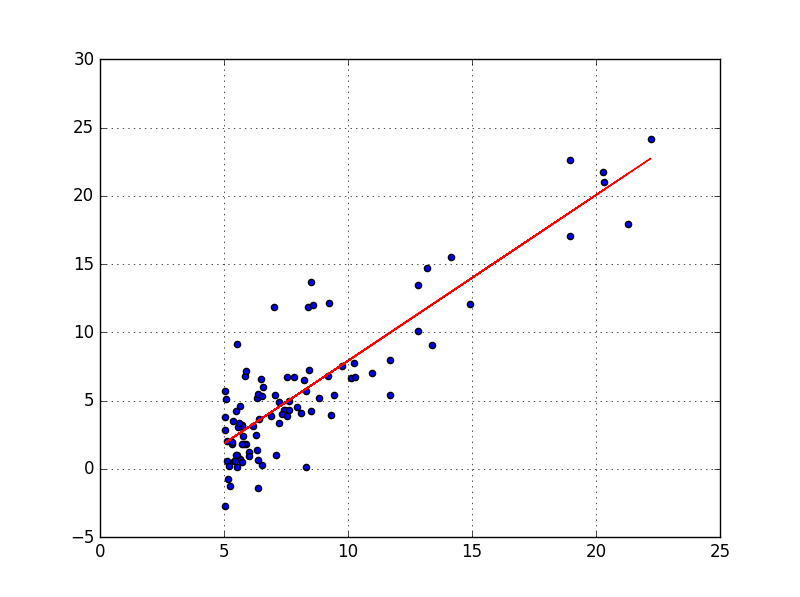
En effet, on voit bien que la ligne rouge, approche le plus possible tous les points du jeu de données. Joli non ? 🙂
Si on prend par hasard, la 22 ème ligne de notre fichier CSV, on a la taille de population qui fait : 20.27 * 10 000 personnes et le gain effectué était : 21.767 * 10 000 $
En appelant la fonction predict() qu’on a défini précédemment :
print predict(20.27)
# return : 20.3870988313On obtient un gain estimé proche du vrai gain observé (avec un certain degré d’erreur)