Importation des Données en Python
Avant toute Analyse de données, Quoi de plus mieux que de connaître les types de données à importer et comment les importer.
Dans ce tutoriel nous allons voir comment importer des fichiers depuis plusieurs sources.
1: Les Fichiers Txt
Un fichier txt est un fichier contenant du texte brut (non formaté) et qui n’exige aucun programme (logiciel) spécial pour l’ouvrir.
Ainsi pour ouvrir un fichier txt en python:
fichier = open('roman.txt',mode='r')
print(fichier.read()) Le code ci-dessus produit le résultant suivant:

Lecture du contenu d’un fichier txt en python
Aussi on peut lire le contenu ligne par ligne :
with open('roman.txt') as file:
print(file.readline())
2. Les fichiers csv
Le fichier csv est un type de fichier dont les valeurs sont séparés par des virgules d’où son sigle CSV (Comma Separated Values). De base le fichier csv contient des données d’un tableau et dont chaque ligne du tableau correspond à une ligne dans le fichier. Avec la bibliothèque pandas on peut lire un fichier cvs comme ceci:
#importation de la bibliothèque pandas
import pandas as pd
#affectation du chemin vers le fichier à la variable file
file = 'titanic_sub.csv'
#lecture du fichier csv avec la fonction read_csv()
data = pd.read_csv(fichier)
#affichage du contenu de data
dataLe bout de code ci-dessus aura comme résultat :

Lecture d’un fichier csv avec pandas
D'autres alternatives sont aussi disponible avec la bibliothèque Numpy:
3. Les fichiers xlsx
Un fichier xlsx est quand à lui un tableur Excel crée par Microsoft. il gère les données dans des feuilles de calcul qui regorgent en eux des cellules disposées en grille de lignes et de colonnes. Il peut contenir aussi des fonctions mathématiques, des graphiques, des styles et une mise en forme. Pour lire le contenu d’un fichier excel:
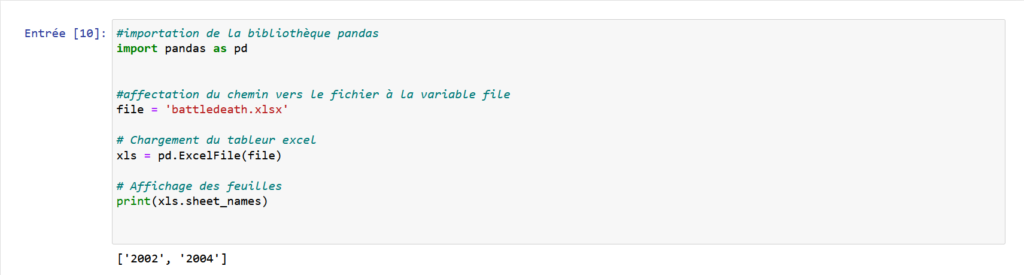
#importation de la bibliothèque pandas
import pandas as pd
#affectation du chemin vers le fichier à la variable file
file = 'battledeath.xlsx'
# Chargement du tableur excel
xls = pd.ExcelFile(file)
# Affichage des feuilles
print(xls.sheet_names)Ainsi on aura comme résultat:
Et pour lire le contenu d’une feuille de calcul excel on peut soit parser sur le nom de la feuille ou sur l’index de la feuille; Comme ceci:
# Charger la feuille dans un DataFrame par nom: df1
df1 = xls.parse('2004')
# Affichage des cinq(5) premieres lignes de la feuille df1
print(df1.head())
# Charger la feuille dans un DataFrame par nom: df2
df2=xls.parse(0)
# Affichage des cinq(5) premieres lignes de la feuille df2
print(df2.head())
4. Les fichiers sas
SAS pour (Statistical Analysis System) est une suite de logicielle statistique développée par SAS Institute pour la gestion des données,l’analyse avancée, l’analyse multivariée,l’informatique décisionnelle, l’analyse prédictive,la veille stratégique etc…
Leurs extensions sont plus couramment sas7bdata pour les jeu de données et sas7bcat pour les catalogue. En python il existe un module sas7bdat qui permet de lire un fichier sas:
#importation SAS7BDAT appartenant au module sas7bdat
from sas7bdat import SAS7BDAT
# Enregistrement du fichier dans un Dataframe: df_sas
with SAS7BDAT('sales.sas7bdat') as file:
df_sas= file.to_data_frame()
# Afficher les 5 premiers lignes
print(df_sas.head())
La sorti sera:

5. Les fichiers stata
Stata est un logiciel de statistiques et d’économétrie largement utilisé par les économistes et les épidémiologistes. Un ficher stata (.dta) peut être lis avec pandas:
# Importation de pandas
import pandas as pd
# Chargement du ficher en dataframe: df
df=pd.read_stata('disarea.dta')
# Affichage des 5 premieres lignes
df.head()
6. Les fichiers MATLAB
Matrix Laboratory où MATLAB est un environnement informatique numérique qui est un standard de l’industrie dans les disciplines de l’ingénierie et des sciences qui prône des puissantes capacités d’algèbre linéaire et de matrice. Un fichier MATLAB a l’extension .mat et est une collection de plusieurs objets (chaînes de caractères, nombres décimale, vecteurs,tableaux, etc….). Pour lire un fichier .mat on a besoin de scipy.io:
# Importation du package
import scipy.io
# Chargement du fichier MATLAB: mat
mat = scipy.io.loadmat('ja_data2.mat')
# Affichage du type de la variable mat
print(type(mat))
Comme constaté la variable est un dictionnaire; Donc on peut voir les différentes clés et pouvoir lire les contenus:
# Importation du package
import scipy.io
# Chargement du fichier MATLAB: mat
mat = scipy.io.loadmat('ja_data2.mat')
# Affichage du type de la variable mat
print(type(mat))
# Affichage des clés du dictionnaire
print(mat.keys())
# Affichage des valeurs de la clé rfpCyt
print((mat['rfpCyt']))

7. Les fichiers SQL
SQL pour Structured Query Language est un langage permettant de communiquer avec les bases de données relationnelles. Dans ce exercice nous allons utiliser une base de donnée SQLite et le package SQLAlchemy pour accéder à cette base de donnée.
Ainsi pour ce créer un moteur de connexion à la base de donnée nous allons utiliser la fonction create_engine() de SQLAlchemy en lui passant en paramètre le type et le nom de la base de donnée:
# Importation du module
from sqlalchemy import create_engine
# Creation du moteur et affectation à la variable engine
engine = create_engine('sqlite:///Chinook.sqlite')
# Affectation des noms des tables à la variable: table_names
table_names= engine.table_names()
# Affichage des noms des tables
print(table_names)
Après avoir créer le moteur de connexion, il est temps de se connecter et d’interagir avec la base de donnée:
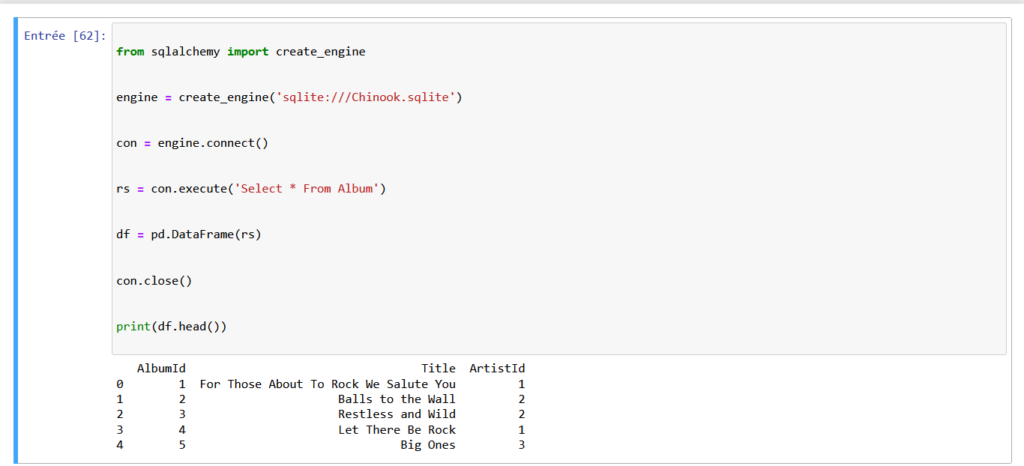
# Ouvir la connexion du moteur: con
con = engine.connect()
# Executer une requête: rs
rs = con.execute('Select * From Album')
# Enregistrer le résultat sous forme de DataFrame: df
df = pd.DataFrame(rs)
# Fermeture de la connexion
con.close()
# Affichage des 5 premieres lignes de la requête
print(df.head())
Voilà on a pus interagir avec la base de donnée avec SQLAlchemy. Une autre alternative plus simple est l’utilisation de Pandas pour interagir directement avec la base de donnée. Ceci en utilisant la fonction read_sql_query et comme paramètres la requête et le moteur de connexion:
from sqlalchemy import create_engine
engine = create_engine('sqlite:///Chinook.sqlite')
# Executer la requête et stocker les lignes dans un DataFrame: df
df = pd.read_sql_query('select * from Album', engine)
# Affichage des cinq(5) premieres lignes
print(df.head())
