Cycle de vie de la science des données.

Tout projet commence par un énoncé de problème bien défini (comme prévoir les ventes d'un article X présent dans son inventaire dans le mois à venir ou la cause du désabonnement des clients) ou un problème mal défini (comme comment augmenter les ventes d'un produit ).
La science des données nous permet de résoudre ce problème commercial avec une série d'étapes bien définies. Généralement, ce sont les étapes que nous suivons le plus souvent pour résoudre un problème commercial. Toutes les terminologies liées à la science des données relèvent de différentes étapes que nous allons comprendre dans un moment
Étape 1: Compréhension commerciale
Étape 2: La collecte de données
Étape 3: Pré-traitement des données
Étape 4: Analyse des données
Étape 5 Modélisation des données
Étape 6: Évaluation du modèle
Étape 7: Déploiement du modèle
Étape 8: générer des informations et générer des rapports BI
Étape 8: Prendre une décision basée sur des idées
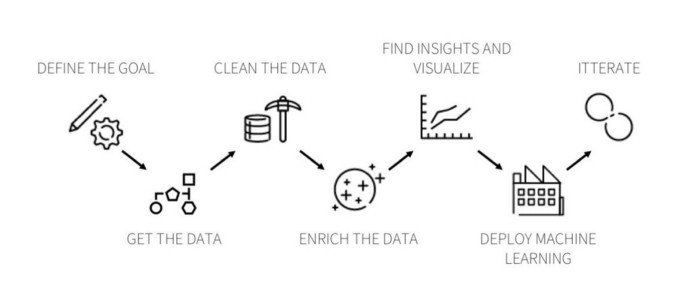
Laissez-nous discuter de ces étapes en détail:
Étape 1: : Compréhension commerciale

Le besoin métier est le point de départ du cycle de vie. Il est donc important de comprendre l'énoncé du problème et de poser les bonnes questions au client, ce qui nous aide à bien comprendre les données et à en tirer des informations significatives.
Nous avons toute la technologie pour nous faciliter la vie, mais avec ce changement énorme, le succès de tout projet dépend de la qualité des questions posées pour l'ensemble de données.
Chaque domaine et chaque entreprise travaille avec un ensemble de règles et d'objectifs. Afin d'acquérir les données correctes, nous devons être en mesure de comprendre l'entreprise. Poser des questions sur l'ensemble de données aidera à le réduire pour corriger l'acquisition de données.
Nous utilisons généralement la science des données pour répondre à cinq types de questions :
- Combien ou combien ? (régression)
- Quelle catégorie ? (classification)
- Quel groupe? (regroupement)
- est-ce bizarre? (Détection d'une anomalie)
- Quelle option faut-il prendre ? (recommandation)
À ce stade. vous devez également identifier l'objectif central de votre projet en identifiant les variables qui doivent être prédites.
Quelques bonnes que d'autres entreprises prospères ont posées par le passé à leurs équipes de science des données
- Uber — Quel pourcentage de temps les conducteurs conduisent-ils réellement ? Quelle est la stabilité de leurs revenus ?
- Oyo Hotels — Quelle est l'occupation moyenne des hôtels médiocres ?
- Alibaba — Quels sont les profits au pied carré de nos entrepôts ?
Toutes ces questions sont une première étape nécessaire avant de pouvoir se lancer dans un voyage en science des données. Après avoir posé la bonne question, nous passons à la collecte de données
Étape 2 : Collecte des données

La première étape du cycle de vie des projets de science des données consiste d'abord à identifier la personne qui sait quelles données acquérir et quand acquérir en fonction de la question à laquelle il faut répondre. La personne ne doit pas nécessairement être un scientifique des données, mais toute personne connaissant la vraie différence entre les différents ensembles de données disponibles et prenant des décisions difficiles concernant la stratégie d'investissement dans les données d'une organisation sera la bonne personne pour le poste.
Il peut être nécessaire de collecter des données à partir de plusieurs types de sources de données.
Quelques exemples de source de données.
- Format de fichier Données (feuille de calcul, CSV, fichiers texte, XML, jSON)
- Base de données relationnelle
- Base de données non relationnelle (NoSQL)
- Scraping des données du site Web à l'aide d'outils
Notre première terminologie, BIG DATA, convient ici. Les mégadonnées ne sont rien d'autre que des données trop volumineuses/complexes à gérer. Les mégadonnées ne signifient pas nécessairement des données importantes en science. Les données volumineuses sont caractérisées par 4 propriétés différentes et si vos données présentent cette propriété, elles sont alors qualifiées d'être appelées données volumineuses. Ces propriétés sont définies par 4 V.
– Volume: Données en téraoctets
– Rapidité: Streaming data with high throughput
– Variety: Structuré, semi-structuré et non structuré
– Véracité la qualité des données analysées
Dans un commerce de détail, de nombreuses transactions sont effectuées chaque seconde par de nombreux clients, de nombreuses données sont conservées dans un format structuré ou non structuré concernant les clients, les employés, les magasins, les ventes, etc. Toutes ces données rassemblées sont trop complexes à traiter ou à traiter. même comprendre. Les technologies Big Data comme Hadoop, Spark, Kafka simplifient notre travail ici.
Étape 3 : Nettoyer les données

Souvent appelée également la phase de lutte contre les données. Les scientifiques des données se plaignent souvent qu'il s'agit de la tâche la plus ennuyeuse et la plus chronophage impliquant l'identification de divers problèmes de qualité des données.
Dans cette étape, nous comprendre plus sur les données et préparez-le pour une analyse plus approfondie. La section compréhension des données de la méthodologie de la science des données répond à la question : les données que vous avez collectées sont-elles représentatives du problème à résoudre ?
C'est une tâche que vous finirez toujours par faire. Nettoyer les données signifie essentiellement supprimer les écarts de vos données tels que les champs manquants, les valeurs incorrectes, définir le bon format des données, structurer les données à partir de fichiers bruts, etc.
Formatez les données dans la structure souhaitée, supprimez les colonnes et les fonctionnalités indésirables. La préparation des données est l'étape la plus chronophage, mais sans doute la plus importante de tout le cycle de vie. Votre modèle sera aussi bon que vos données. Ceci est similaire au lavage des légumes pour éliminer les produits chimiques de surface. Collecte de données, compréhension des données et préparation des données prendre jusqu'à 70% — 90% du temps global du projet.
C'est également le point où si vous pensez que les données ne sont pas appropriées ou suffisantes pour que vous puissiez continuer, vous revenez à l'étape de collecte de données.
Étape 4 : Analyse des données

EXPLOREZ… EXPLOREZ… EXPLOREZ
L'analyse exploratoire est souvent décrite comme une philosophie, et il n'y a pas de règles fixes sur la façon de l'aborder. Il n'y a pas de raccourcis pour l'exploration des données.
N'oubliez pas que la qualité de vos entrées détermine la qualité de votre sortie. Par conséquent, une fois que vous avez préparé votre hypothèse commerciale, il est logique d'y consacrer beaucoup de temps et d'efforts.
Pour comprendre les données , beaucoup de gens regardent les statistiques de données comme la moyenne, la médiane, etc. Les gens tracent également les données et regardent leur distribution à travers des graphiques comme l'histogramme, l'analyse du spectre, la distribution de la population, etc..
Maintenant, nous créons un plan pour faire des analyses sur les données. Il peut y avoir différents types d' analyse de données qui peuvent être effectuées sur les données en fonction du problème à résoudre. Différents types d'analyses peuvent inclure comme ci-dessous :
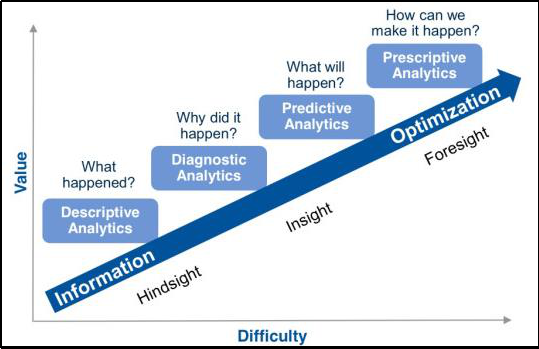
💡 Analyse descriptive (que s'est-il passé dans le passé ?)
Nous pouvons utiliser des outils de méthodes d'agrégation de données pour fournir des informations sur ce qui s'est passé dans le passé.
💡 Analyse prédictive (que pourrait-il se passer dans le futur ?)
Nous pouvons utiliser des méthodes statistiques et d'autres techniques de prévision, notamment l'exploration de données et l'apprentissage automatique, pour comprendre et estimer ce qui pourrait se passer dans le futur.
💡 Analyse prescriptive (que faire ?)
Nous pouvons utiliser des méthodes d'optimisation et de simulation pour prendre la décision et décrire les résultats possibles pour l'analyse de simulation et si-quoi
Cette étape du cycle de vie du projet de science des données ne produit aucune information significative. Cependant, grâce au nettoyage régulier des données, les data scientists peuvent facilement identifier les faiblesses du processus d'acquisition de données, les hypothèses qu'ils doivent faire et les modèles qu'ils peuvent appliquer pour produire des résultats d'analyse.
Donc, nous déterminons d'abord quel type d'analyse nous avons l'intention d'effectuer. Cela fait partie de l'analyse des données. Après avoir obtenu des données structurées à partir des opérations de nettoyage (ce qui est généralement le cas), nous effectuons l'opération d'exploration de données afin d'identifier et de découvrir des modèles et des informations cachés dans un grand ensemble de données. Ceci est connu comme exploration de données.
Par exemple, identifier la saisonnalité des ventes. L'analyse des données est l'approche la plus holistique, mais l'exploration de données a tendance à trouver les modèles cachés uniquement dans les données. Ces modèles découverts sont alimentés par des approches d'analyse de données adoptées pour générer des hypothèses et trouver des informations.
Étape 5 : Modélisation des données/Modélisation de l'apprentissage automatique

Cette étape semble être la plus intéressante pour presque tous les data scientists. Beaucoup de gens l'appellent "une scène où la magie opère". Mais rappelez-vous que la magie ne peut se produire que si vous avez les bons accessoires et la bonne technique. En termes de science des données, "Données" est cet accessoire, et la préparation des données est cette technique. Donc, avant de passer à cette étape, assurez-vous de passer suffisamment de temps dans les étapes précédentes.
La modélisation est utilisée pour trouver des modèles ou des comportements dans les données. Ces modèles nous aident de deux manières :
- modélisation descriptive (apprentissage non supervisé) — Systèmes de recommandation qui sont si une personne a aimé le film Matrix, elle aimerait aussi le film Inception ou
- modélisation prédictive (apprentissage supervisé) — Cela implique d'obtenir une prédiction sur les tendances futures, par ex. régression linéaire où nous pourrions vouloir prédire les valeurs boursières

Enseignement supervisé:
L'apprentissage supervisé est une technique dans laquelle nous enseignons ou formons la machine à l'aide de données bien étiquetées.
Pour comprendre l'apprentissage supervisé, considérons une analogie. En tant qu'enfants, nous avions tous besoin de conseils pour résoudre des problèmes de mathématiques. Nos professeurs nous ont aidés à comprendre ce qu'est la dépendance et comment cela se produit. De même, vous pouvez considérer l'apprentissage supervisé comme un type d'apprentissage automatique qui implique un guide. L'ensemble de données étiqueté est l'enseignant qui vous apprendra à comprendre les modèles dans les données. L'ensemble de données étiqueté n'est rien d'autre que l'ensemble de données d'apprentissage.
La photo ci-dessous montre l'apprentissage supervisé. Ce faisant, vous formez la machine en utilisant des données étiquetées. Dans l'apprentissage supervisé, il y a une phase de formation bien définie effectuée à l'aide de données étiquetées.
Quelques exemples d'algorithmes supervisés :
- Bayes naïf
- Forêt aléatoire
- Algorithmes de réseau de neurones
- k-Voisin le plus proche (kNN)
- Régression linéaire
- Régression logistique
- Machines vectorielles de soutien (SVM)
- Arbres de décision
- Booster
- Ensachage
Apprentissage non supervisé :
L'apprentissage non supervisé implique une formation en utilisant des données non étiquetées et en permettant au modèle d'agir sur ces informations sans aucune aide. Considérez l'apprentissage non supervisé comme un enfant intelligent qui apprend sans aucune orientation.
Quelques exemples d'algorithmes non supervisés :
- APC
- Kmoyennes/Kmoyennes++
- Classification hiérarchique
- DBSCAN
- Analyse du panier de consommation
Vous trouverez ci-dessous certaines des pratiques standard impliquées pour comprendre, nettoyer et préparer vos données pour la construction de votre modèle prédictif :
- Identification des variables
- Analyse univariée
- Analyse bivariée
- Traitement des valeurs manquantes
- Traitement des valeurs aberrantes
- Transformation variable
- Création de variables
Enfin, nous devrons répéter plusieurs fois les étapes 4 à 7 avant de proposer notre modèle raffiné.
Étape 6 : : Évaluation du modèle

Une question courante que les professionnels se posent souvent lors de l'évaluation des performances d'un modèle d'apprentissage automatique dans lequel l'ensemble de données qu'ils doivent utiliser pour mesurer les performances du modèle d'apprentissage automatique. L'examen des métriques de performance sur l'ensemble de données formé est utile mais n'est pas toujours correct car les chiffres obtenus peuvent être trop optimistes car le modèle est déjà adapté à l'ensemble de données de formation. Les performances des modèles d'apprentissage automatique doivent être mesurées et comparées à l'aide d'ensembles de validation et de test pour identifier le meilleur modèle en fonction de la précision et du sur-ajustement du modèle.
Sur la base des modèles de problèmes commerciaux pourraient être sélectionnés. Il est essentiel d'identifier quelle est la tâche, s'agit-il d'un problème de classification, de régression ou de prédiction, de prévision de séries chronologiques ou d'un problème de regroupement. Une fois le type de problème résolu, le modèle peut être mis en œuvre.
Quelques exemples de Métriques de classification:
- Précision de la classification
- Matrice de confusion
- Perte logarithmique (perte de journal)
- Aire sous la courbe (AUC)
- Mesure F (Score F1)
- Précision
- Rappeler
Quelques exemples de Métriques de régression:
- Erreur absolue moyenne (ou MAE)
- Erreur quadratique moyenne (MSE)
- Erreur quadratique moyenne (RMSE)
- MAPE
Le modèle doit être robuste et non sur-ajusté. S'il s'agit d'un modèle sur-ajusté, les prédictions pour les données futures ne seront pas exactes.
Étape 7 : générer des informations et des rapports de BI

Dans ce processus, les seules compétences techniques ne suffisent pas. Une compétence essentielle dont vous avez besoin est d'être capable de raconter une histoire claire et exploitable. Si votre présentation ne déclenche pas d'actions chez votre auditoire, cela signifie que votre communication n'a pas été efficace. Il devrait être en ligne avec les questions d'affaires. Il doit être significatif pour l'organisation et les parties prenantes. La présentation par visualisation doit être telle qu'elle déclenche l'action du public. N'oubliez pas que vous présenterez à un public sans connaissances techniques, donc la façon dont vous communiquez le message est essentielle.
Quelques outils utilisés à des fins Viz :
- Tableau
- Power BI
- R — ggplot2, lattice
- Kibana
- Grafana
- Spotfire
- Python — Matpoltlib, Seaborn, Plotly.

Étape 8 : Déploiement du modèle

Après avoir créé des modèles, il est d'abord déployé dans un environnement de pré-production ou de test avant de les déployer réellement en production.
Whatever the shape or form in which your data model is deployed it must be exposed to the real world. Once real humans use it, you are bound to get feedback. Capturing this feedback translates directly to life and death for any project.
Quelques frameworks utilisés pour le déploiement du modèle :
- Flask
- Django
- FastAPI
Les fournisseurs de cloud populaires et largement utilisés sont,
- AWS
- Azure
- Google Cloud
Étape 9 : Prendre des mesures

Les informations exploitables du modèle montrent comment la science des données a le pouvoir de faire des analyses prédictives et des analyses prescriptives. Cela nous donne le pouvoir d'apprendre à répéter des résultats positifs ou à prévenir des résultats négatifs.
Sur la base de toutes les informations que nous avons recueillies grâce à l'observation des données ou au résultat du modèle d'apprentissage automatique, nous entrons dans un état où nous pouvons prendre des décisions concernant tout problème commercial à résoudre.
Quelques exemples sont :
- Quelle quantité de stock de l'article X devons-nous avoir en inventaire ? Quelle remise faut-il accorder à l'article X pour augmenter ses ventes et maintenir le compromis entre remise et profit ?
- Quelle est l'attrition prévue et que peut-on faire pour éviter la même chose ?
Chaque étape a sa propre importance et passera par plusieurs itérations dans les deux sens. Plusieurs personnes de différentes piles techniques travailleront en coordination pour réaliser un livrable réussi.
Par conséquent, enfin et surtout, la communication avec plusieurs équipes est indispensable pour une réalisation plus fluide du projet.